As part of my day job I occasionally need to give workshops on using OpenShift, Red Hat's distribution of Kubernetes. The workshop notes that attendees follow to do the exercises we host using an internally developed tool called workshopper. We host the workshop notes using this tool inside of the same OpenShift cluster that users will be working in.
To access the OpenShift cluster and do the exercises, attendees use the OpenShift command line clients oc or odo. They may also need to use kubectl. Because these are client side tools they would need to be installed somewhere where the attendees can run them, usually this is on their own local computer.
Requiring that attendees install a client on their own local computer can often be a challenge. This is because when dealing with enterprise customers, their employee's computers may be locked down such that they are unable to install any additional software.
A solution one often sees to this problem is to enhance the tool used to host the workshop notes to embed an interactive terminal which is then used through the web browser. Behind the scenes that terminal would be connected up to some backend system where a shell environment is run for the specific user accessing the workshop. Finally, in that shell environment they would have access to all the command line tools, as well as other files, that may be needed for that workshop.
In my case, modifying the workshopper tool didn't look like a very attractive option. This is because it was implemented in Ruby, a programming language I don't know. Also, because workshopper only hosted content, it knew nothing of the concept of users and authentication, nor did it have any ability itself to spawn up separate isolated shell environments for each user.
Rather than modify the existing workshopper tool, another option would be to swap it out and use an open source tool such as Open edX which already encompassed such functionality. A problem with using Open edX is that it has a very large footprint and is way more complicated than we needed. The OpenShift clusters we used for training might only be running for a day, and setting up Open edX and loading it with content for the workshop would be a lot more work and wouldn't provide the one click setup solution we were after.
After thinking about the problem for a while it dawned on me, why not use JupyterHub, a tool I was well familar with and had already done a lot of work with around making it work on OpenShift and be easy to deploy.
Now you may be thinking, but JupyterHub is for spawning Jupyter notebook instances, how does that help. Although the Jupyter notebook web interface does have the capability to spawn an interactive terminal in the browser, it would be a quite confusing workflow for a user to access it in this way.
This is true, but what most people who may have been exposed to JupyterHub probably wouldn't know is that you don't have to use JupyterHub to spawn Jupyter notebooks. JupyterHub can in fact be used to spawn an arbitrary application, or when we are talking about Kubernetes, an arbitrary container image can be used for the per user environment that JupyterHub creates.
What does JupyterHub provide us?
JupyterHub calls itself a "multi-user server for Jupyter notebooks". It is made up of three sub systems:
- a multi-user Hub (tornado process)
- a configurable http proxy (node-http-proxy)
- multiple single-user Jupyter notebook servers (Python/IPython/tornado)
The architecture diagram from the JupyterHub documentation is shown as:
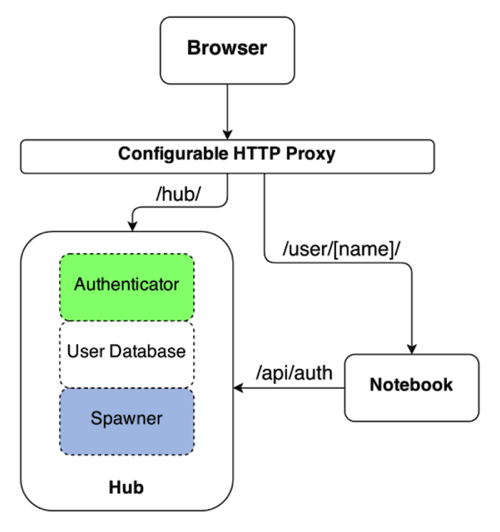
As already noted, you aren't restricted to spawning Jupyter notebooks, it can be used to spawn any long running application, albeit usually a web application. That said, to integrate properly with JupyterHub as the spawner and proxy, the application you run does need to satisfy a couple of conditions. We'll get to what those are later.
The key things we get from JupyterHub by using it are:
- can handle authentication of users using PAM, OAuth, LDAP and other custom user authenticators
- can spawn applications in numerous ways, including as local processes, in local containers or to a Kubernetes cluster
- proxies HTTP traffic, and monitors that traffic, facilitating detection and culling of idle application instances
- provides an admin web interface for monitoring and controlling user instances of an application
- provides a REST API for controlling JupyterHub and, monitoring and controlling user instances of an application
With these capabilities already existing, all we had to do for our use case was to configure JupyterHub to perform user authentication against the OAuth provider endpoint of the same OpenShift cluster they were using for the workshop. Next we configure JupyterHub to be able to spawn an application instance for each user as a distinct pod in Kubernetes.
The workflow for the user would be to visit the URL for the JupyterHub instance. This would redirect them to the login page for the OpenShift cluster where they would log in as the user they had been assigned. Once successfully logged in, they would be redirected back to JupyterHub and to their specific instance of an interactive terminal accessible through their web browser.
This interactive terminal would provide access to a shell environment within their own isolated pod in kubernetes. The image used for that pod is pre-loaded with the command line tools so they are all ready to go, without needing to install anything on their own local computer. The pod can also be backed by a per user persistent volume, so that any changes made to their workspace will not be lost in the event of their instance being restarted.
So the idea at this point is not to try and augment the original workshopper tool with an embedded terminal, but to provide access to the per user interactive terminal in a separate browser window.
In browser interactive terminal
In some respects, setting up JupyterHub is the easy part as through the prior work I had been doing on deploying JupyterHub to OpenShift, I already had a suitable JupyterHub image, and a workflow for customising its configuration to suit specific requirements.
What was missing and had to be created was an application to provide an in browser interactive terminal, except that I didn't need to even do that, as such an application already exists, I just had to package it up as a container image for JupyterHub to deploy in Kubernetes.
The application I used for the in browser interactive terminal was Butterfly. This is a Python application implemented using the Tornado web framework. It provides capabilities for handling one or more interactive terminal sessions for a user.
Because I was needing to deploy Butterfly to Kubernetes, I needed a container image. Such an image doesn't exist on DockerHub, but I couldn't use that. This is because to ensure access is fully protected and that only the intended user can access a specific instance, you need to perform a handshake with JupyterHub to verify the user. This is the first of those conditions I mentioned, and what is represented by the /api/auth call from the notebook to JupyterHub in the JupyterHub architecture diagram.
A second condition was the ability to force the web application being created for each user, to be hosted at a specific base URL. This is where you see only web traffic for /user/[name] being directed to a specific notebook instance in the JupyterHub architecture diagram. Butterfly already supported this capability, or at least it tried to. The hosting at a sub URL in Butterfly was actually broken, but with a bit of help from Florian Mounier, the author of Butterfly, I got a pull request accepted and merged which addressed the problem.
Coming up next, the terminal image
To cover all the details is going to be too much for a single post, so I am going to break everything up into a series of posts. This will include details of how the terminal application image was constructed and what it provides, as well as how JupyterHub was configured.
I will also in the series of posts explain how I then built on top of the basic functionality for providing a set of users with their own interactive terminal for the workshop, to include the capability to embed that terminal in a single dashboard along with the workshop notes, as well as potentially other embedded components such as the ability to access the OpenShift web console at the same time.
As the series of posts progresses I will reveal how you might try out what I have created yourself, but if eager to find out more before then, you can ping me on Twitter to get any conversation started.